ChatGPT开发团队收集了海量的优质文档作为语料库,并对语料属性进行标注,使用神经网络算法进行训练,使其能像人类一样聊天、编写文案、编程等。ChatGPT还引入了强化学习,实现了在与人类互动时,能根据用户反馈进行迭代优化。
某校园大门出入口“智能门禁系统”采用人脸识别或刷校园卡的方式识别出入人员。本校人员识别通过,自动开启闸机,并将学生出入学校的相关信息发送给家长:外来人员需通过闸机伴侣拍照登记后方可开启闸机,相关数据上传到服务器;系统管理员具备设置门禁参数、查看出入记录、管理数据库等特殊权限。该系统的主要组成部分如图所示:

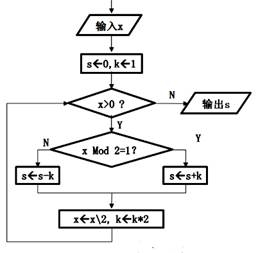
import random
d=[28, 37, 39, 42, 45, 50, 70, 80]
i, j, n=0, len(d)-1, 0
key=random.randint(20, 35)*2
while i<=j:
m=(i+j)//2; n+=1
if key==d[m]:
break
elif key<d[m]:
j=m-1
else:
i=m+1
print(i, j, m, n)
执行该程序段后,下列说法正确的是( )

|
序号 |
子页面路径 |
功能说明 |
|
1 |
/ |
实时显示温湿度数据 |
|
2 |
/input |
提交温湿度数据 |
|
3 |
lcount |
显示温湿度统计数据 |
|
4 |
/search |
查询显示某一天的历史数据 |
sta=1
if t>tmax:
sta=1
sta=0
B . sta=0if t<tmin:
sta=1
elif t>tmax:
sta=1
C . if t<tmin or t>tmax:sta=1
else:
sta=0
D . sta=1if t<=tmax:
sta=0
elif t>=tmin:
sta=0

该球迷想根据历史赛季数据预测各球队下个赛季的首发阵容,编写了如下Python程序,请回答下列问题:
import pandas as pd
def readData(file):
df=pd.read_excel(file) #读取文件 file 中的数据
cols={"二分":2,"三分":3,"罚球":1}
for i in range(len(df)): #计算每个队员的得分
for col in cols:
p=df[col][i].find("-")#在字符串中找到“-”的位置
n=float(df[col][i][:p])
return df
def select(teams) :
#teams 是字典变量,如:{"浙江":0,"上海":1},字典的值代表球队编号
seasons=["20-21","21-22","22-23"]
members=[0]*len(teams)*2
df=readData(seasons[0]+".x1sx")
for season in :
file=season+".xlsx"
df1=readData(file)
df=pd.concat([df, df1])#合并两个 DataFrame 对象数据
for team in teams:
df1=
df1=df1.groupby("球员" , as_index=False).mean()#计算各球员平均得分
df1=df1.sort_values("得分",ascending=False).head(5)#按得分降序排序并选取前5名
members[2*n]=df1["球员"].values
members[2*n+1]=df1["得分"].values
return members
import matplotlib.pyplot as plt
def showChart(tean, menbers) :
n=teams[team]
plt.bar(,)
plt.title(team+"队首发阵容")
plt.show()
⑷主程序代码如下。
teams={"浙江":0,"上海":1,"山东":2,"广东":3,"北京":4}
members=select (teams)
while True:
team=input("输入球队:")
if team=="" : break
showChart(team, members)
文件结束块用-1 表示,空闲盘块用 0xff 表示。

函数 regain 的功能是模拟数据恢复,找到各个文件的起始地址和大小(盘块数量),并返回以[[起始地址, 文件大小], …]形式的列表 lst。变量 allot 存储文件分配表信息。
def regain(allot):
lst=[]
visited=[] #记录 allot 的访问情况
for i in range(len(allot)):
if allot[i] != 0xff and i not in visited: #盘块 i 需要处理
fsize=0
p=i
while p!=-1 and p not in visited:
visited.append(p)
fsize+=l
p=allot[p]
if p==-1:
lst.append([i,fsize])
else:
for j in range(len(Ist)):
if lst[j][0]==p:
lst[j][0]=i
lst[j][1]=lst[j][1]+fsize
return lst
若allot为[3,7,13,9,0xff,0xff,0xff,8,-l,-l,0xff,l,0,1l,0xff,0xff],调用regain函数,
①则语句 lst[j][1]=lst[j][1]+fsize 一共会被执行次。
②如果把 while p!=-1 and p not in visited 改写为 while p!=-1,对程序的影响是(多选,填字母)。
A.会增加 while 的循环体执行次数
B.返回的 lst 中的节点数量保持不变
C.while 循环不能正常结束
D.返回的 lst 中,文件的起始地址部分不正确

如图 2所示,共有3个空闲盘区,盘块号依次为 4、5、6、10、14、15请在划线处填上合适的代码。
def mergefree(allot): #mergefree 的功能是从头到尾扫描文件分配表,创建空白盘区链
freeh=-1:freelst=[]
n=len(allot)
i=0
while i<n:
if allot[i]==0xff:
j=i+1
while
j+1
freelst.append([i,j-i,-1])
if freeh==-1:
freeh=cur=len(freelst)-1
else:
freelst[cur][2]=len(freelst)-1
i=j+l
else:
i+=l
return freeh,freelst
#读取文件分配表信息存储到 a11ot 中,代码略
head,freelst=mergefree(allot)
p=head
whi1e p!=-1: #打印出所有空闲盘块号
for i in range(freelst[p][1]):
print(,end=',')
p=freelst[p][2]
