请回答下面小题。
num=input("请输入数字串:");c=0
![]()
for i in range(1,len(num)):
if ![]() and f==False:
and f==False:
f=True
elif ![]() and f==True:
and f==True:
c=c+1
f=False
print("有",c,"座数字山峰")
方框(1)(2)(3)的代码由以下部分组成:
①f=True ②f=False ③num[i-1]>num[i] ④num[i-1]<num[i]
下列选项中代码顺序正确的是( )
from random import randint
n=input("请输入一串数字:")
k=randint(0,len(n)) #randint用于随机生成[0,len(n)]之间的整数
for i in range(k):
for j in range(len(n)-1):
if n[j]>n[j+1]:
break
else:
n=n[:len(n)-1]
continue #continue跳过当前循环的剩余语句,直接进行下一轮循环
n=n[:j]+n[j+1:]
执行该程序段后,输入“1529”,则变量n可能是( )
|
图1 | 图2 |
操作步骤:小墩得1分,按下Micro:bit主板的按钮A,左侧比分区亮点加1;小融得1分,按下按钮B,右侧比分区亮点加1。一局比赛初始比分为0:0,每一局中先达到10分的选手可以赢得该局。
from microbit import *
def bf(x,y):
#在led板上显示比分情况,代码略
m=0;n=0 #m表示小墩得分,n表示小融得分
while True:
if button_a.is_pressed(): #若按钮A被按下,则小墩得1分
m+=1
elif button_b.is_pressed(): #若按钮B被按下,则小融得1分
n+=1
if :
if m>n:
print("第",i,"局:小墩赢,比分:",m,":",n)
else:
print("第",i,"局:小融赢,比分:",m,":",n)
i+=1;m,n=0,0
bf(m,n)
sleep(200) #设置程序运行间隔为200毫秒
 B .
B .  C .
C .  D .
D . 
|
图1 |
图2 |
为分析数据,小张编写了如下程序:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
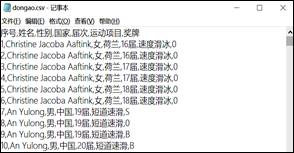
df=pd.read_csv("dongao.csv")
#删除所有未获得奖牌的记录,并将奖牌列中的"G"修改为"金牌","S"修改为"银牌","B"修改为"铜牌"
jp={'G':'金牌','S':'银牌','B':'铜牌'}
for i in df.index:
if ① :
df=df.drop(i)
else:
df.at[i,'奖牌']=jp[df.at[i,'奖牌']]
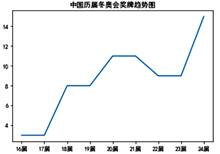
#对输入国家每届的奖牌数进行统计,并制作相应图表,如第14题图2所示:
nt=input("请输入国家名称:")
df1=df[df['国家']==nt]
![]()
df3=pd.DataFrame(df2) #将分组后数据生成新的二维结构,索引为“届次”,列标题为“奖牌”
x=df3.index
y= ②
plt.title(nt+"历年冬奥会奖牌趋势图")
plt. ③ (x,y)
plt.show()
df2=df1.届次.count()
B . df2=df1.groupby('届次')df2=df2['奖牌'].count()
C . df2=df1.groupby('奖牌')['届次’].count() D . df2=df1.groupby('届次').奖牌.count()|
图1 |
图2 |
图3 |
选择加密时,在明文文本框中输入明文,点击“加密”按钮,网页显示密文与对应的密钥。加密规则为打乱明文对应的索引作为密钥,再利用该索引逐个取明文字符连接成密文,例如:明文为“信息技术”,若被打乱的索引为[2,0,1,3],则密文为“技信息术”,密钥为“2,0,1,3”
选择解密时,在密文文本框中输入密文,密钥文本框输入密钥,点击“解密”按钮,网页显示明文。
from flask import render_template,request,Flask
import random
app=Flask(__name__) #创建应用实例
@app.route('/') #选择页面路由
def index():
return render_template('')
#加密功能代码略,以下为解密代码:
@app.route('/jiemi1/',methods=["GET","POST"])
def jiemi1():
wb=request.form["wb"] #利用request获取网页文本框内容,返回示例:“1,4,2,3,0”
keyo=request.form["key"] #变量wb存储密文,变量keyo存储密钥
keyn=list(map(int,keyo.split(","))) #将字符串keyo转换为数值列表,示例:[1,4,2,3,0]
result=""
for i in range(len(keyn)):
for j in range(len(keyn)):
if :
break
result+=wb[j]
return render_template("jie.html",WB=wb,KEY=keyo,RESULT=result)
if __name__=="__main__":
def cal(lst): #计算样本lst的信息熵
x,y,z=0,len(lst),0 #x表示该样本信息熵,y表示该样本数量,z表示某信息发生的概率
num={}
for i in lst:
if i not in num:
num[i]+=1
for k in num:
z=num[k]/y #计算该信息发生的概率
x-=z*log(z,2) #根据公式计算信息熵,log(b,a)等价于logab
return x
def check(x,y):
#根据节点x,对样本y进行划分,返回示例:{'否': [1, 1, 0, 0, 1, 1, 1, 1], '是': [1, 1, 0, 1, 0, 0]}
dic={'是否有风': ['否', '否', '否', '否', '否', '否', '否', '否', '是', '是', '是', '是', '是', '是'],
'天气': ['多云', '多云', '晴', '晴', '晴', '雨', '雨', '雨', '多云', '多云', '晴', '晴', '雨', '雨'],
'温度': [28, 27, 29, 22, 21, 21, 20, 24, 18, 22, 26, 24, 18, 21],
'湿度': [78, 75, 85, 90, 68, 96, 80, 80, 65, 90, 88, 63, 70, 80],
'是否前往': [1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0]}
xm=list(dic.keys())
entropy=cal(dic[xm[-1]]) #调用函数计算样本原始信息熵entropy
#计算各节点信息增益
m=0;p=""
col=xm[:-1] #“是否前往”是结果项,不参与计算
for i in col:
size=len(dic[i]);entropy_1=0
zyb= #调用函数对样本按照当前节点进行划分
for j in zyb: #根据划分情况逐个求子样本信息熵并按比例累加
entropy_1+=len(zyb[j])/size*cal(zyb[j])
zy=entropy-entropy_1
print(i,"的信息增益:",zy)
if zy>m: #计算最大信息增益与信息增益最大的节点
m=zy
print("信息增益最大的节点:",p)
|
图1 | 图2 |
通过了解当天的是否有风、天气、温度和湿度这4个节点参数即可预测当天是否有人来游乐场。
不同的节点划分顺序可以绘制不同的决策树,为了选出最优的节点划分顺序,需要采用“信息熵”与“信息增益”指标。
信息熵,又称香农熵,被用来度量信息量的大小,信息熵越大表示信息量越大;
信息增益,表示样本经某节点划分后的信息熵变化大小。我们绘制决策树时应当逐次选择信息增益最大的节点作为当前节点。
对于有n个信息的样本D,记第k个信息发生的概率为,信息熵计算公式为E(D)=,
例如游乐场14个样本中“去”(9个)、“不去”(5个),则信息熵==0.940
若样本按“是否有风”节点划分,“是”(6个,其中3个去,3个不去)信息熵==1;
“否”(8个,其中6个去,2个不去)信息熵==0.811;经过此节点划分后的信息增益=原始信息熵按此节点划分后样本信息熵比例和=0.940(0.811)=0.048。
from flask import render_template,request,Flask
import random
app=Flask(__name__) #创建应用实例
@app.route('/') #选择页面路由
def index():
return render_template('')
#加密功能代码略,以下为解密代码:
@app.route('/jiemi1/',methods=["GET","POST"])
def jiemi1():
wb=request.form["wb"] #利用request获取网页文本框内容,返回示例:“1,4,2,3,0”
keyo=request.form["key"] #变量wb存储密文,变量keyo存储密钥
keyn=list(map(int,keyo.split(","))) #将字符串keyo转换为数值列表,示例:[1,4,2,3,0]
result=""
for i in range(len(keyn)):
for j in range(len(keyn)):
if :
break
result+=wb[j]
return render_template("jie.html",WB=wb,KEY=keyo,RESULT=result)
if __name__=="__main__":
def cal(lst): #计算样本lst的信息熵
x,y,z=0,len(lst),0 #x表示该样本信息熵,y表示该样本数量,z表示某信息发生的概率
num={}
for i in lst:
if i not in num:
num[i]+=1
for k in num:
z=num[k]/y #计算该信息发生的概率
x-=z*log(z,2) #根据公式计算信息熵,log(b,a)等价于logab
return x
def check(x,y):
#根据节点x,对样本y进行划分,返回示例:{'否': [1, 1, 0, 0, 1, 1, 1, 1], '是': [1, 1, 0, 1, 0, 0]}
dic={'是否有风': ['否', '否', '否', '否', '否', '否', '否', '否', '是', '是', '是', '是', '是', '是'],
'天气': ['多云', '多云', '晴', '晴', '晴', '雨', '雨', '雨', '多云', '多云', '晴', '晴', '雨', '雨'],
'温度': [28, 27, 29, 22, 21, 21, 20, 24, 18, 22, 26, 24, 18, 21],
'湿度': [78, 75, 85, 90, 68, 96, 80, 80, 65, 90, 88, 63, 70, 80],
'是否前往': [1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0]}
xm=list(dic.keys())
entropy=cal(dic[xm[-1]]) #调用函数计算样本原始信息熵entropy
#计算各节点信息增益
m=0;p=""
col=xm[:-1] #“是否前往”是结果项,不参与计算
for i in col:
size=len(dic[i]);entropy_1=0
zyb= #调用函数对样本按照当前节点进行划分
for j in zyb: #根据划分情况逐个求子样本信息熵并按比例累加
entropy_1+=len(zyb[j])/size*cal(zyb[j])
zy=entropy-entropy_1
print(i,"的信息增益:",zy)
if zy>m: #计算最大信息增益与信息增益最大的节点
m=zy
print("信息增益最大的节点:",p)